在当下这个数字化时代,监控平台的高效运行显得尤为关键。一旦发现异常,必须迅速处理故障,同时还要有效管理资源,这些都是企业所高度重视的问题。
异常通知很关键
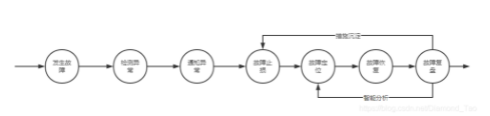
一旦发现异常,平台必须确保信息传达无误。正如众多互联网企业所做,故障一旦出现,必须立即通知研发或运维团队。这样做是为了迅速减少损失。若是小问题,人工处理可能迅速解决。然而,若遇到严重故障,中枢决策平台可能需要介入,看是否可以自动修复。在大型数据中心,故障每延长一分钟,损失可能巨大。因此,通知必须迅速进行。这一切关乎平台系统信息传递的效率,若该机制不够高效,故障处理过程将大大延长。
从另一个角度看,告知相关人员不只是让他们了解问题所在,更是提醒他们着手分析问题的根本原因。无论是现场立即处理,还是后续的调查,这都是首要步骤。以金融企业为例,这些企业的业务连续性要求极高,一旦故障通报延迟,不仅客户体验会受损,还可能引发金融风险。
故障根因定位
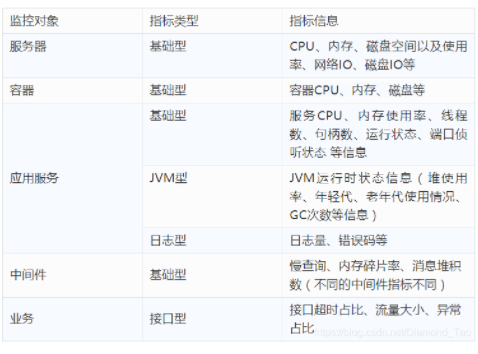
此时,平台或研发团队需积极应对。需针对发现的问题追根溯源。以电商平台为例,若订单系统突然出现问题,研发人员需分析是服务器内存不足,还是程序存在缺陷。若为程序缺陷,还需进一步确定是代码的哪个部分。随后,根据具体情况决定是修复还是升级。在北京的一家互联网公司,其运维团队曾遭遇服务器频繁断线的问题。经细致排查,发现系一个程序的小失误导致资源占用过多,他们迅速修复了这一错误,并对服务器进行了适当的升级。
业务增长过程中,若类似问题频繁发生,甚至涉及全新场景下的故障类型,我们必须持续积累和总结排查经验。不同业务场景中的故障往往与众多其他因素有关联,需要我们进行全面分析。以在线教育平台为例,在直播高峰时段出现卡顿,这或许不只是服务器的问题,还可能涉及网络带宽和预估的在线人数等因素。
AI提升处理能力
如果平台的AI智能化程度较高,那就相当不错。在不少新兴科技公司里,他们持续向AI输入各类新的故障类型和场景。比如,一种新型的网络攻击导致平台部分功能出现问题,AI能够从中吸取经验。随后,在策略库中更新相应的处理方法。以阿里的一些数据业务部门为例,他们在此领域持续深入研究,利用AI模拟各种可能的故障,并提出解决方案,这对提升整体业务的安全性大有裨益。
若新策略持续更新,平台的自愈能力将逐步增强。这对减轻运维和研发团队的工作压力极为关键。过去可能需人工耗时数小时排查和修复的问题,AI学习后或许仅需几分钟就能解决。
数据采集是基础

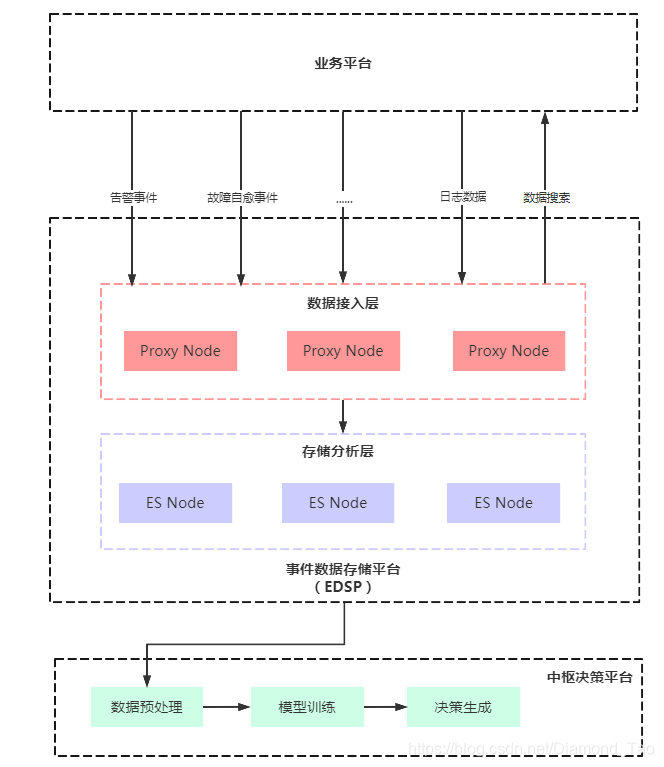
数据采集是监控平台的基础。以电商平台为例,若想了解各地订单的即时状况、商品库存量等信息,必须依赖不断的数据收集。在后续的业务流程中,这些收集到的监控数据将被广泛应用。对于一些大型跨国电商平台,他们每天需要收集大量的交易数据,而这些数据正是通过遍布全球的采集点来完成的。
数据采集若不够充分或存在误差,那么整个监控平台就如同盲人摸象。缺乏精确全面的数据,各监控环节的判断极易失误。全国范围内的电商仓库、配送中心等各环节的数据必须详尽收集,以确保后续监控有可靠依据。
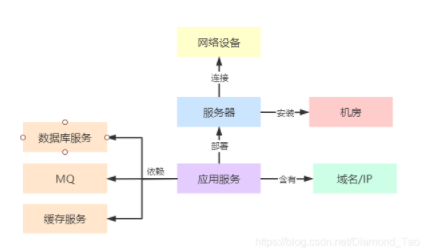
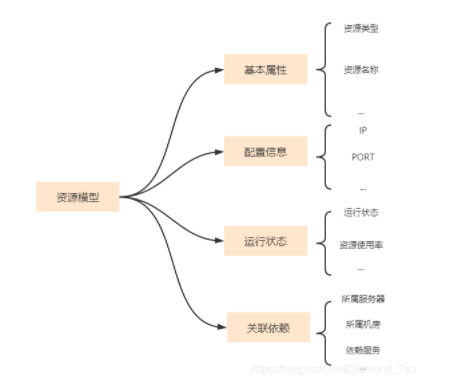
CMDB的核心价值
在这个过程中,CMDB扮演着至关重要的角色。它负责管理各种资源模型和基础数据。以某软件开发公司为例,不同项目所需的开发工具和资源配置都由CMDB进行管理。这使得监控平台上的各类应用能够便捷地调用资源。就像是为大家搭建了一个资源库,查找资源变得十分方便。
从各个业务领域来看,CMDB实现了资源的有效整合。以游戏开发为例,无论是制作不同游戏场景还是角色建模,所需资源都能在CMDB中找到相应的模型和数据。这对提高开发速度和优化项目间资源利用至关重要。
故障定位新方法
为了确定故障根源,现在有了新的手段。我们可以通过筛选故障区域、进行多角度的关联分析来锁定关键问题。对于拥有多个数据中心的企业来说,这种方法尤为实用。再者,若能运用AI技术对分析模型进行训练,未来或许连人工干预都无需进行故障定位。以腾讯云的部分服务为例,一旦出现故障,便可通过后台的关联分析迅速定位问题。
一旦发现业务接口响应时间过长,我们便可以进行详细分析。这包括识别受影响的应用和服务实例,确认它们部署的位置,检查对应机房的服务器是否负载过重,以及相关服务和中间件是否运行正常。通过这种方式,我们可以从一个小小的接口超时问题出发,逐步扩大调查范围,然后再逐步缩小至最有可能出现故障的具体位置。
我们已了解这些监控平台的关键点。大家在使用工作或上网服务时,是否遇到过因监控不足或故障处理不当导致的糟糕体验?若觉得本文有益,请点赞并转发。