
在推荐场景里,确保向用户准确推荐商品非常关键。本文将介绍一种方法,该方法通过计算用户对商品的偏好来衡量相似度,以此达到精确推荐的目的。
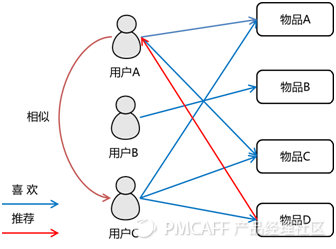
推荐基本原理
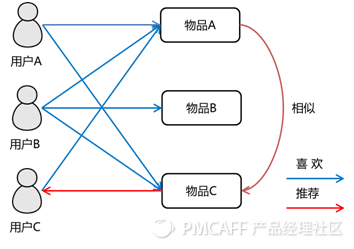
为了实现精准推荐,我们依赖用户与物品偏好的双维度表格。具体方法有两种:首先,把每位用户对不同物品的偏好看作一个向量,以此来衡量用户间的相似度;其次,把每位用户对某一特定物品的偏好也视为一个向量,以此来评估物品间的相似度。这两种方法极其依赖相似度计算,需借助相似度来辨别“相近”的用户或商品,从而完成推荐。
斯皮尔曼相关性
斯皮尔曼相关性是一种基于用户喜好值排列的Pearson相关度。这种相似度的结果只能是正负1。这是由于我们需确定用户的喜好值是否与User1的喜好值同步变动或相反变动,比如用户对产品的评分走势是否与User1的一致。
Tanimoto Coefficient

Tanimoto系数与以往的计算方式存在较大不同。它并不侧重于用户对物品的具体评价,而是聚焦于用户与物品之间的联系。通过计算这些联系,我们能推测出用户对物品的偏好程度,也就是推荐指数。这就像不考虑你对电影的打分,只看你是否观看过某些电影一样。
用户推荐步骤:找物品集合
首先,需要完成两项任务。第一项是找出用户以往偏好的商品,第二项是掌握用户尚未感兴趣的物品。前者将作为推荐算法的依据,后者则是推荐商品的根本。以电商网站为例,这涉及到识别用户过去购买或放入购物车的商品,还包括那些尚未被查看的商品。
用户推荐步骤:计算相似度
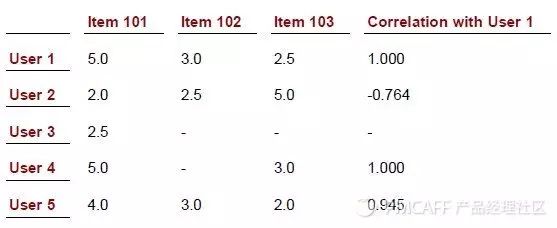
有了前两个集合,我们接下来要研究它们之间的相互关系。这种关系表现为一种多对一的模式,即一个未受偏好的物品与用户所有已偏好的物品之间的联系。我们用相似度这个标准来衡量这种关系。掌握了相似度之后,我们就能理解不同物品与用户已喜爱物品之间的关联程度。
用户推荐步骤:计算推荐值
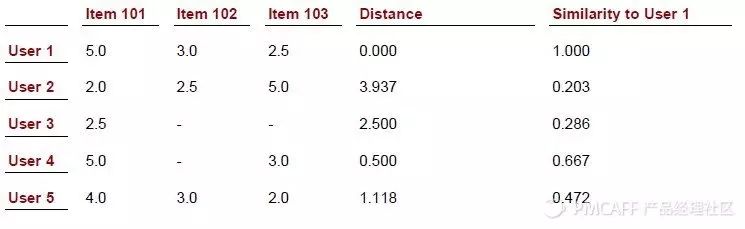
这种一对多的关系使得我们能够计算物品对特定用户的推荐指数。这通常是通过将物品与用户喜好的相似度相乘得出。以Item_i和Item_x为例,如果它们之间的相似度较大,并且用户对Item_x的喜爱程度也较高,那么Item_i对这位用户的推荐指数也有可能相对较高。同样,邻居所提的计算方式涉及将他们对物品的喜爱程度与用户和邻居间的相似度相乘。
在使用这些推荐方法时,大家认为哪种方式在衡量相似度上更为合适?不妨点赞、转发本篇文章,并在评论区分享您的看法。